Models of Information Exploration:
Where is the broader task?
Morgan N. Price
FX Palo Alto Laboratory, Inc.
http://www.fxpal.xerox.com/people/price
price@pal.xerox.com
Position paper for the CHI98 workshop on information exploration interfaces
Abstract
Existing models of information exploration focus on collecting information without examining the collection activity as part of a broader task. I use a writing scenario to highlight the transitions between collecting information and other activities, and propose an extension to Marchinonini’s (1995) model of information seeking that makes these more transitions explicit. Based on this extension, I describe four transitions that today’s interfaces don’t support, relate each transition to work practices, and briefly describe how to support each transition. We should study these transitions in more detail, especially the role of paper in these transitions, and design information exploration interfaces systems that support them.
A Writing Scenario
Imagine an academic writing the related work section of a paper. Consider all the questions that he or she faces: What should I say? Have I read enough relevant papers, or should I do a literature review? Which papers are relevant? What does the previous work mean for my paper?
In practice, academics first decide whether the effort of digging through the literature seems worthwhile. Then, they search and browse for relevant papers, print them out (or order copies), and sort through them on paper. They read, annotate, and compare the most important papers; connect the important ideas together; and try to make some coherent sense of them. As they read, they find references to more relevant papers. Eventually, they return to writing their paper, and use the key information they found by digging through their notes or through piles of paper.
This scenario raises more general issues with information exploration as a process that people go through to solve their problems. They must decide whether information exploration is the appropriate strategy by predicting whether helpful information is available and how much effort will be required to find it. They must collect a manageable amount of relevant information by browsing or searching; if there is too much material available, as is often the case, they must select articles to read by rapidly scanning them. They must understand how this information relates to their problem: understanding one document can be difficult enough; often they must connect ideas from disparate sources together. Finally, they must apply this understanding to their problem, which may require looking through their piles of papers and typing in information. In sum, this scenario suggests that we should take the broader task into account throughout the information exploration process.
Information Exploration Models and the Broader Task
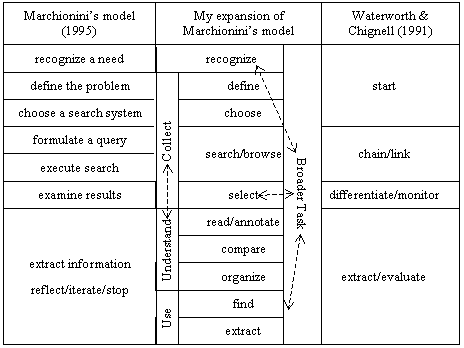
Existing theories of information exploration, however, present the process of collecting information as disjoint from the broader task. For example, in Marchionini’s (1995) model of information seeking behavior, the user acts on their main task only at the beginning step of recognizing a need and at the penultimate step (before deciding whether to stop) of extracting information; the five intermediate steps represent the details of collecting information. These models do consider the context and purpose of information seeking, and use concepts of information needs and relevance to represent how the user thinks about their task while collecting information, but the assumption is still that users working on their main task and users collecting information are largely separate.
Table 1: Models of information exploration
This separation between collecting information and the broader task, reflected both in theories and in interfaces, leads to two important omissions. First, what do users actually do with the information they collect? How do they understand it and use it to solve their problems? Second, what happens to the broader task as they collect information?
I have tried to address these omissions by expanding Marchionini’s model (see Table 1) to reflect the processes in the writing scenario. I’ve distinguished understanding the collected information—reading, annotating, and organizing it—from using it—finding and extracting the most useful information. I’ve eliminated the "reflect/iterate/stop" process because completing the broader task should be the final step, and because the transitions between stages are unpredictable, so why describe reflection and iteration as a separate step? And I’ve made explicit four transitions between sub-processes that the writing scenario highlights:
These four transitions are neither explicit in most models of information exploration, nor supported by existing interfaces. The following sections argue that these transitions are important problems, not just for the hypothetical scenario but for real work, and suggest how interfaces might support them.
Recognizing the need for more information in the broader task
The transition from the main task to collecting information is burdensome. Although a rough representation of users’ interests is already available (e.g., the academic’s paper outline or draft), interfaces for collecting information require that users communicate their interests separately. Furthermore, users do not receive any feedback that relevant documents might be available until they risk a significant amount of effort to find out; users cannot predict whether the effort of information exploration is likely to pay off.
Interfaces that suggest relevant documents during reading (as in Schilit et al, 1998) and writing (as in Rhodes and Starner, 1996) could minimize the transition to information gathering, and help users predict whether information gathering will be worthwhile. Systems for linking from paper documents to computer displays (e.g., Arai et al, 1997) could support the transition from paper-tasks to information exploration.
Selecting information based on the broader task
Today’s interfaces do not directly help users select information that relates to their task. Instead, they help users understand how hits (retrieved documents) relate to each other, or to the structure of the collection as a whole. To quote from the call for papers for this workshop, information visualizations should try to show "adequate representations of the retrieved results and their relationship to the rest of the collection" (Golovchinsky and Belkin, 1998).
Information explorers often run repeated searches and write up descriptions of what they have learned (O’Day and Jeffries, 1993). Why not help connect retrieved information to what they’ve already written? Similarly, if users have already organized or annotated some of the documents that they’ve collected for this task, then visualizations could relate hits to those annotations.
Collecting information versus understanding it
Many users work with retrieved documents on paper: they print them out, mark on them, compare them, and organize them (Marshall, 1990; O’Day and Jeffries, 1993). Although deep reading is often required to understand the retrieved information, most interfaces don’t address the difficulties with reading on desktop computers (O’Hara and Sellen, 1997), and thus the information exploration process moves between collecting information online and understanding it on paper.
These transitions between media are disruptive (Price et al, 1998). Because searching online is easy but printing is slow, users go through iterations of collecting information without really understanding how that information relates to the their task. This contributes to information overload, and a work practice called information triage: people collect many documents online, print them out, and skim them for useful information (Marshall and Shipman, 1997). Unfortunately, when people actually read what they’ve collected, they often realize that it’s not what they were looking for.
Computers can support understanding information, not just collecting it. Although computers cannot match all of the advantages of paper for reading, information exploration interfaces should at least let users annotate, compare, and organize retrieved documents. Paper-like pen computers can support deep reading (Schilit et al, 1998) and help users organize material as they read it (Price et al, 1998). Marshall and Shipman (1997) show that spatial hypertext can be a lightweight way to organize retrieved documents.
This transition also raises open questions about reading and information exploration. The studies I’ve cited are several years old, and much more material is now available online. People probably continue to print out most of what they read carefully, but how much are they reading online? Are they just picking relevant documents online (perhaps with greater care, now that they can look at the full text and not just abstracts)? Are they using less paper, or more paper?
Applying the understanding to the broader task
It is often awkward to use gathered information in the original application. The most useful information is generally found by reading on paper, and the digital source of the information may not be conveniently available. Marshall (1990) describes one analyst who prepares for writing a report by typing in verbatim highlighted text, and adding bibliographic and reliability information! If interfaces for reading online become acceptable, then this practice can be automated by extracting the annotated text (as in Schilit et al, 1998).
Marshall’s study also points out that when analysts collect and organize a lot of material, finding the relevant information in that organization becomes a task in itself. Information exploration interfaces should support directed search through these personal collections.
Research Directions
In summary, information exploration is more than collecting information. Interfaces can and should support the transition from the main task to information gathering, and help users understand information as they find it. Further work is needed to understand how information exploration might be integrated into different types of tasks, and how the transitions between the broader task, collecting information, and understanding information affect the overall process.
References
Arai, T., Aust, D. Hudson, S.E. (1997) PaperLink: A Technique for Hyperlinking from Real Paper to Electronic Content. In Proceedings of CHI97 (Atlanta, GA, March 1997), pp. 327-334, ACM Press.
Belkin, N.J. (1993) Interaction with Texts: Information Retrieval as Information-Seeking Behavior. In Information Retrieval 93: von der Modellierung zur Anwendung. Proceedings of the First Conference of the Gesselschaft für Informatik Fachgruppe Information Retrieval (pp. 55-66) Konstanz: Universitätsverlag Konstanz.
Golovchinsky, G. and Belkin, N.J. (1998) Innovation and Evaluation in Information Exploration Interfaces. In CHI98 Conference Companion, ACM Press. To appear.
Marchionini, G. (1995) Information Seeking in Electronic Environments. Cambridge University Press, 1995.
Marshall, C.C. (1990) Work Practices Study: Analysts and Notetaking. Unpublished report, 31 May 1990.
Marshall, C.C. and Shipman, F.M. (1997) Spatial Hypertext and the Practice of Information Triage. In Proceedings of Hypertext ’97, Southampton UK, ACM Press, p. 124-133.
O'Day, V.L. and Jeffries, R. (1993) Orienteering in an Information Landscape: How Information Seekers Get From Here to There. In Proceedings of INTERCHI ’93, ACM Press, pp.438-445.
O’Hara, K. and Sellen, A. (1997) A Comparison of Reading Paper and On-Line Documents. In Proceedings of CHI97 (Atlanta, GA, March 1997), ACM Press, pp. 335-342.
Price, M.N., Golovchinsky, G., and Schilit, B.N. (1998) Linking By Inking: Trailblazing in a Paper-like Hypertext. In Proceedings of Hypertext '98, ACM Press. To appear.
Rhodes, B.J. and Starner, T. (1996) A continuously running automated information retrieval system. In Proceedings of The First International Conference on The Practical Application of Intelligent Agents and Multi Agent Technology (PAAM '96), London, UK, April 1996, pp. 487-495.
Schilit, B.N., Golovchinsky, G. and Price, M. (1998) Beyond Paper: Supporting Active Reading with Free-form Digital Ink Annotations. In Proceedings of CHI98, ACM Press. To appear.
Waterworth, J.A. and Chignell, M.H. (1991) A model for information exploration. Hypermedia 3(1):35-58.